Transfer Learning in Deep RL
The general idea of transfer learning is to reuse learnings or experiences from related tasks to obtain a jumpstart on the task of interest. A lot of work in this paradigm in RL is centered around learning from easier but related tasks to generalize to a desired, harder task.
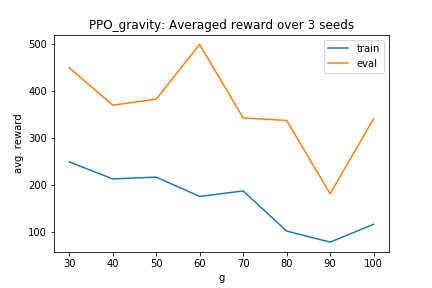
A recently published work on Challenge Learning [Jason Ma, 2019] explores the other direction of transfer. It proposes learning policies on a harder version of an environment and evaluating the same on an easier one by controlling a single environment variable. The paper, however, only demonstrates experimental results on CartPole using an Advantage Actor Critic (A2C) [Mnih et al., 2016] architecture.
We added evaluations of the environment on an actor-critic architecture using Proximal Policy Optimization (PPO) [Schulman et al., 2017] as the actor, which is known to be much more robust to changes in the environment. We also controlled for an extra variable, the magnitude of the horizontal force applied on the cart (a constant).